Did you know that PDF files often serve as a gateway for cyberattacks? These seemingly harmless documents can be infected with dangerous viruses that damage to your computer without you realizing it. Viruses often hide in PDF files to exploit security vulnerabilities and steal your sensitive data.
In this blog post, we show you how you can check PDFs for viruses to ensure the security of your documents. Find out how you can effectively protect yourself from PDF cyberattacks with a few simple steps!
Table of contents
Why are PDF Files Popular for Phishing Attacks
PDF files (Portable Document Format) are used on a daily basis both at work and by private individuals. PDFs have also evolved into documents with advanced features such as interactive forms, multimedia content and scripts. For this reason, PDF documents can be weaponized through malicious use of the features above to compromise systems and steal data.
Attackers will create PDF files with malicious links or scripts and send them as an attachment to the most convincing email they can craft, in an attempt to exploit user trust. Here you can find out how to recognize such phishing emails.
As a result, PDF documents are also a popular tool for cyber criminals to use in phishing attacks. When the user interacts with the PDF, for example by clicking on the link, they can be redirected to a phishing website or malware may be downloaded.
Structure of a PDF File and Possible Attack Vectors
In order to be able to analyze PDF files, it is important to understand their structure. A PDF file is structured as follows:
- Header: Indicates the PDF version used.
- Body: Contains all the data of the document that is displayed to the user (text, images, etc.) and consists of objects.
- Cross-reference table (xref): Contains the references to every object.
- Trailer: Describes where the cross-reference table and other special objects for displaying the document are located.
A PDF file therefore consists of objects that use keywords such as /Size etc. to specify how the document should be displayed. However, there are also keywords that can indicate that the content is potentially dangerous, e.g:
- /JS, /JavaScript: Contains JavaScript.
- /AcroForm, /XFA: Interactive PDF forms, can also contain JavaScript.
- /RichMedia, /EmbeddedMedia: Embedded (Flash) programs.
- /Launch: Launch campaigns.
- /URI: Calls a URL, possibly for phishing.
- /SubmitForm, /GoToR: Can send data to a URL.
The combination of several keywords, e.g. automatic action and JavaScript, makes a PDF document very suspicious.
Dynamic vs. Static Analysis of PDF Documents
The quickest way to determine whether a PDF document is malicious is to check its cryptographic hash value with an online service such as VirusTotal. If this hash value is still unknown, a dynamic analysis using a sandbox can provide additional information about the document. But be careful with free sandbox services: If the document is a legitimate internal document, it is potentially made publicly accessible when it is uploaded! For this reason, static analysis in a virtual machine is a safer alternative.
Tools for PDF Virus Scanning
The following process can be used to statically analyze a PDF document and is described in more detail in this article:
- Use pdfid.py to get an overview of risky features of the PDF file and to assess its properties.
- Use pdf-parser.py or peepdf.py to examine certain objects in more detail.
- Extract embedded code, e.g. shellcode, PowerShell, JavaScript, and de-obfuscate if necessary (not explained in the rest of the article).
By using various tools, false positives and false negatives can be avoided or at least reduced to a minimum. The results of the individual tools can be compared with each other and assessed in terms of their similarity and consistency. This process serves to increase reliability and confidence in the results.
Case Study: Static Analysis of a PDF File
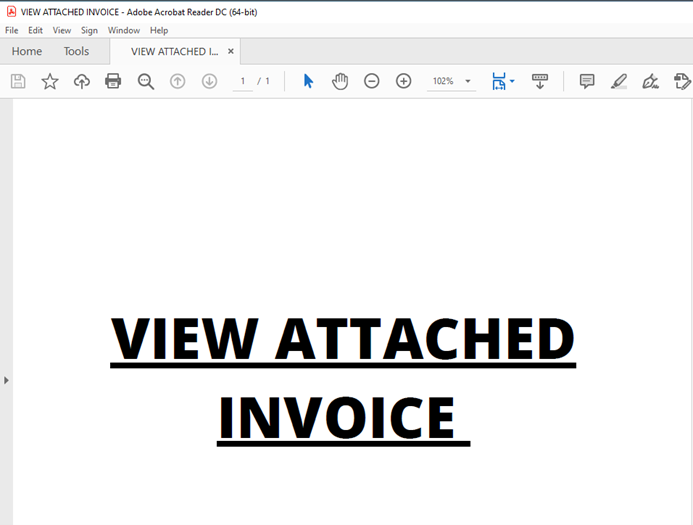
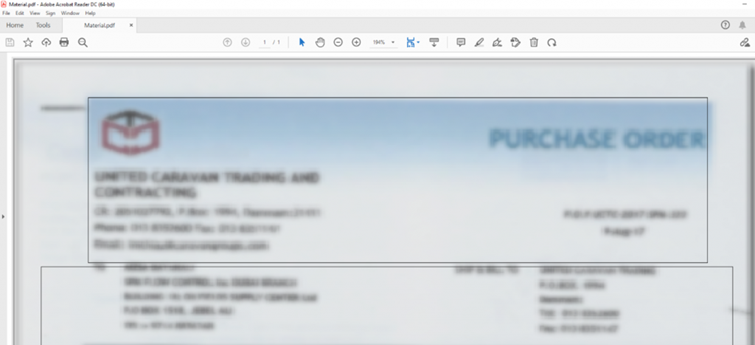
In this article, the two PDF files shown, “View Attached Invoice.pdf” and “Material.pdf“, are analyzed using this procedure as an example.
Caution! When analyzing malicious PDFs, the surrounding system may be compromised, which is why all of the following activities should be carried out in a virtual machine without network access.
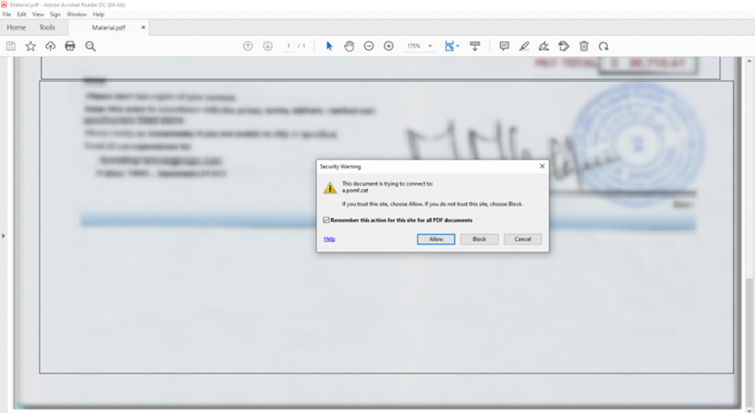
Embedded programs are only started with the user’s permission, i.e. when the document is opened, a window appears with a security warning (see Figure 3). This security setting is activated by default in Adobe and Reader X, 9.3 and 8.2 (see adobe advanced security setting for PDF files). The user must then decide whether to allow or block access, as can be seen in Figure 3 for the second document. If an attacker has sent a malicious PDF file under a credible pretext, there is a high probability that the user will ignore this warning and allow the malicious code it contains to be executed.
Analysis With pdfid.py
pdfid.py is a tool by Didier Stevens that searches for specific PDF keywords for initial analysis. In this case, the result of pdfid.py is as follows:
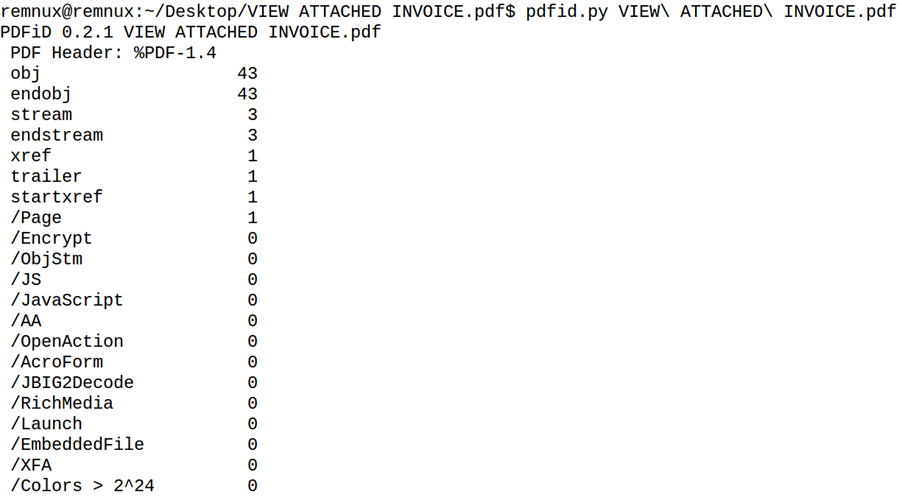
Here, the /Page flag shows that the document is one page long, which is common for malicious PDFs. Otherwise, there is nothing noticeable at first glance, as the other flags have a null value. Accordingly, the document does not contain any JavaScript (/JavaScript and /JS) and no embedded interactive forms (/AcroForm and /XFA). It does not launch any external or embedded programs (/Launch and /EmbeddedFiles), nor does it open automatically (/AA and /OpenAction).
Despite no clear signs of a malicious document, it is recommended to continue the investigation with another tool such as pdf-parser.py. pdfid.py is not comprehensive and does not indicate, for example, whether the document refers to links that could be malicious. Therefore, the content of the document should be analysed in more detail.
Analysis With pdf-parser.py
pdf-parser.py is also a tool developed by Didier Stevens. It parses the various elements of the PDF file and displays their content.
This tool also offers the possibility to search for keywords using the “-s” parameter. In this example, searching for “URI” returns the following result:
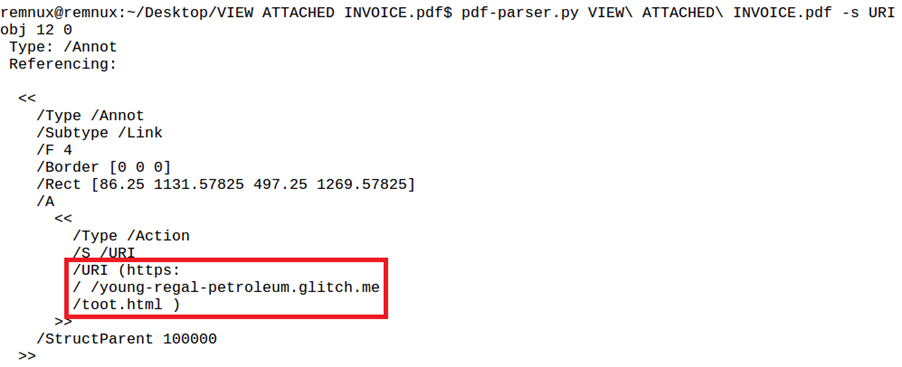
This URI (see red box in Figure 5) is a link as an annotation (see “Type: /Annot”) in object 12.
A search on urlscan.io shows that this is a phishing page targeting Adobe. From the screenshot below, it can be seen that it asks for the user’s email credentials in order to read the document.
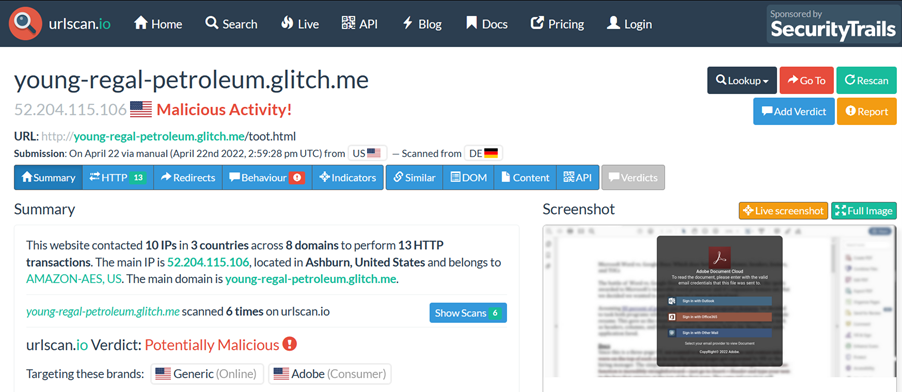
So the goal of the PDF document is to get the credentials for the Adobe Cloud account of the concerned user.
Analysis With peepdf.py
peepdf.py can be used as an alternative to pdfid.py and pdf-parser.py. It provides an interactive shell that can be used to navigate through the structure of the PDF file and search its content. The tool also indicates when it finds suspicious elements.
For Material.pdf, the result is as follows:
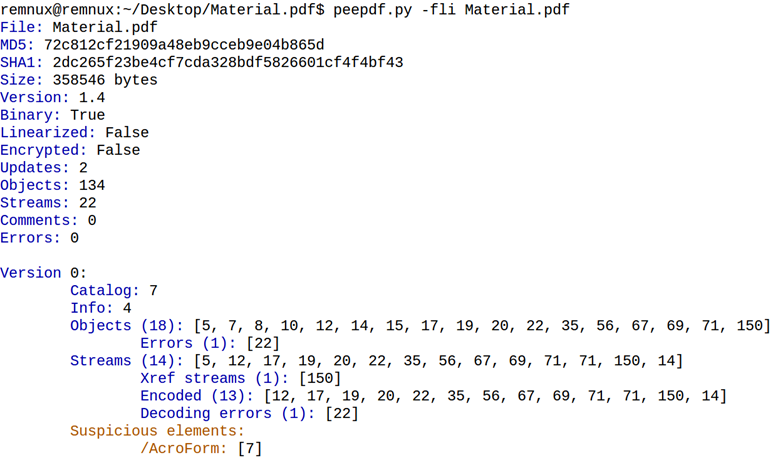
peepdf.py found three suspicious objects, one in version 0 and two in version 2 of the document. /AcroForm (object 7) and /Launch (objects 173 and 65) can be used to embed interactive forms and launch external or embedded programs, respectively.
Object 173 is of particular interest here because it points to a URL:
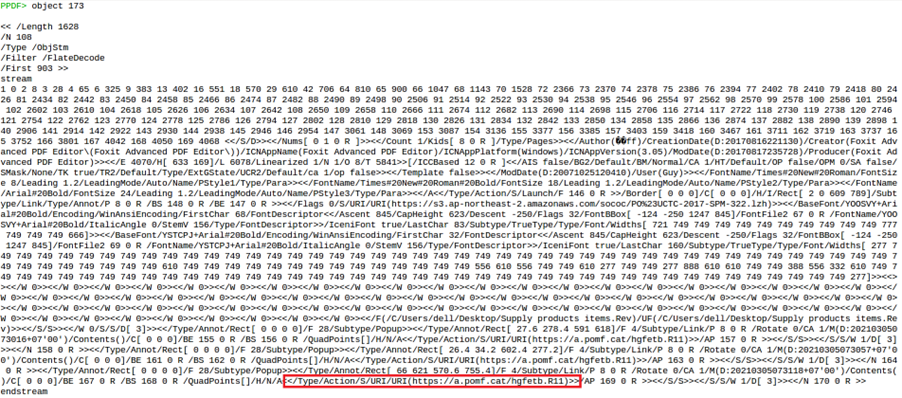
This URL was also visible in the warning message (see Figure 3).
A search on urlscan.io shows that the file “hgfetb.R11” is downloaded via this URL and that this file is a RAR archive (see red box in Figure 9).
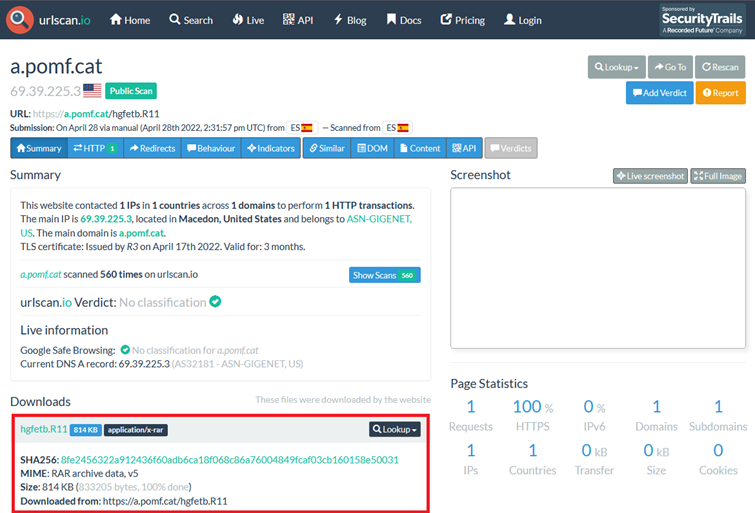
Figure 9: Result of Scan of File “hgfetb.R11” on urlscan.io
VirusTotal also points out that this file has been classified as malicious by several security products.
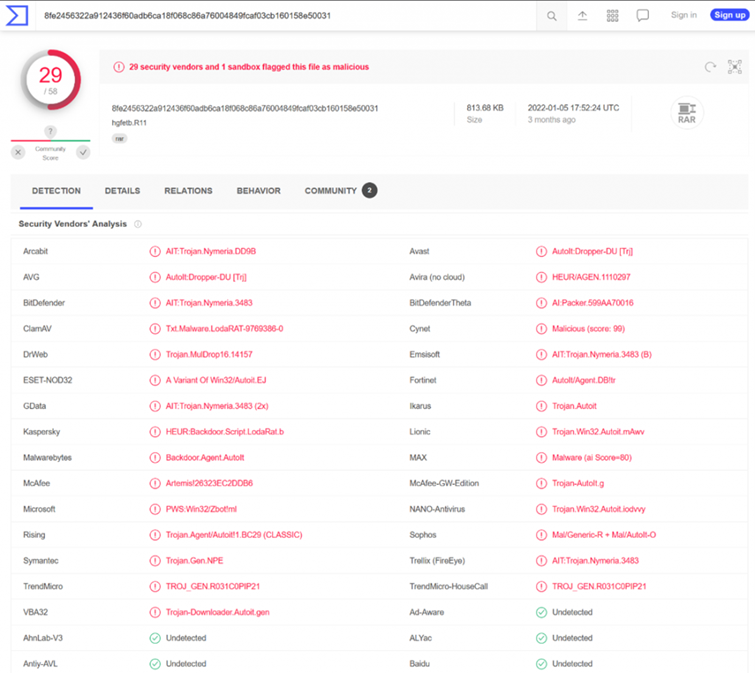
Figure 10: Result of Scan of File “hgfetb.R11” with VirusTotal
Thus, the aim of this PDF file is to make the victim download malicious software.
Conclusion
As a useful alternative to sandboxes, a static analysis can quickly determine whether a PDF document is malicious and what its characteristics are. By using the analysis techniques and tools presented, you can identify potential threats and protect your digital integrity. But security doesn’t end with the document – it starts with the user. Therefore, invest in cybersecurity awareness training for your employees and strengthen your first line of defense against cyberattacks.
If you have any questions or would like support with implementation, our Digital Forensics team is happy to help.