
Ein Überblick über die OWASP Top 10 Proactive Controls mit Beschreibungen der einzelnen Controls, Good Practices und Beispielen zur Umsetzung.
Man könnte sagen, dass die OWASP Top 10 Proactive Controls (präventive Sicherheitsmaßnahmen) im Vergleich zu anderen bekannteren Top-Ten-Listen der OWASP – beispielsweise die zehn kritischsten Risiken für Webanwendungen («OWASP Top 10») oder APIs («OWASP API Security Top 10») – ein wenig aus der Reihe schlagen, denn sie gehen über die bloße Beschreibung von möglichen Risiken hinaus: Die Proactive Controls richten sich primär an Entwickler und geben ihnen konkrete Maßnahmen für die Entwicklung sicherer Anwendungen an die Hand. Darüber hinaus dienen sie dazu, bei Entwicklern das Bewusstsein für die immense Bedeutung von Anwendungssicherheit zu stärken.
Dieser erste Teil des zweiteiligen Artikels beschreibt die Proactive Controls C1 bis C5, im folgenden zweiten Teil werden C6 bis C10 näher betrachtet.
Einführung
Das Open Web Application Security Project (OWASP) ist eine Non-Profit-Organisation, die sich seit 2001 für die Sicherheit von Webanwendungen einsetzt. Bekannt wurde OWASP dabei vor allem durch die eingangs genannten «OWASP Top 10», eine Auflistung der wichtigsten Sicherheitsrisiken für Webanwendungen, die erstmals im Jahr 2003 herausgegeben wurde.
Dieser Artikel soll einen kurzen Überblick über die OWASP Top 10 Proactive Controls geben. Die einzelnen Sicherheitsmaßnahmen sind in absteigender Reihenfolge nach Wichtigkeit sortiert und folgen innerhalb der Auflistung derselben Struktur: Zunächst wird jede Proactive Control beschrieben, gefolgt von Good Practices und Beispielen zur Implementierung. Abschließend werden in Anlehnung an die OWASP Top-Ten-Risiken Schwachstellen aufgeführt, die durch die Implementierung der jeweiligen Maßnahme verhindert werden. Zudem werden Referenzen, beispielsweise die OWASP Cheat Sheets, sowie nützliche Tools genannt.

OWASP zählt die folgenden präventiven Sicherheitsmaßnahmen als die zehn wichtigsten Proactive Controls auf [1]:
- C1: Festlegung von Sicherheitsanforderungen
- C2: Nutzung von Sicherheitsframeworks und Bibliotheken
- C3: Sicherer Zugriff auf Datenbanken
- C4: Encodierung und Maskierung von Daten
- C5: Validierung aller Eingaben
- C6: Implementierung einer Benutzerverwaltung
- C7: Durchsetzung von Zugriffskontrollen
- C8: Durchgängiger Schutz von Daten
- C9: Implementierung von Logging und Monitoring
- C10: Behandlung von Fehlern und Ausnahmen
C1: Festlegung von Sicherheitsanforderungen
C1 (Define Security Requirements) beschreibt die Notwendigkeit, beim Entwickeln von Software Sicherheitsanforderungen zu definieren. Gemäß OWASP ist eine Sicherheitsanforderung eine Aussage über erforderliche Sicherheitsfunktionalität, die eine von vielen Software-Sicherheitseigenschaften erfüllt. Derartige Anforderungen können von Industriestandards, geltender Gesetzgebung oder vergangenen Schwachstellen abgeleitet werden. Sie legen neue Funktionen oder Ergänzungen zu vorhandenen Funktionen fest, um so ein bestimmtes Sicherheitsproblem oder eine mögliche Schwachstelle zu beheben.
Als Grundlage kann hier der OWASP Application Security Verification Standard (ASVS) herangezogen werden; der ASVS ist ein Katalog mit Sicherheitsanforderungen sowie Kriterien zur Überprüfung der Sicherheit von Anwendungen. Er kann von verschiedenen Benutzern – unter anderem Entwicklern, Testern und Tool-Anbietern – zum Entwickeln, Testen und Überprüfen sicherer Anwendungen eingesetzt werden. Der Standard legt dabei drei verschiedene Verifikationsebenen fest, die abhängig vom Schutzbedarf und der Kritikalität von Applikationen angewendet werden können. Zudem umfasst der ASVS verschiedene Kategorien, wie Authentifizierung und Fehlerbehandlung, die Good Practices und überprüfbare Aussagen für die jeweilige Kategorie enthalten. [2] Gemäß C1 sollten diese grundlegenden Aussagen durch konkrete Use Cases bzw. Misuse Cases angereichert werden, sodass eine noch eindeutigere Überprüfung möglich ist. Zum Beispiel sieht der ASVS 4.0 vor, dass Benutzer ein Passwort mit einer Länge von mindestens 12 Zeichen verwenden (V2.1.1). Ausgehend von dieser allgemeinen Aussage ist somit zu prüfen, ob die von den Benutzern einer Anwendung festgelegten Passwörter mindestens 12 Zeichen lang sind. Ein Use Case hierzu könnte wie folgt lauten: «Als Benutzer muss ich ein Passwort wählen, das mindestens 12 Zeichen lang ist, damit die Sicherheitsanforderungen der Anwendung erfüllt werden.» Ein Misuse Case hingegen wird aus Sicht eines möglichen Angreifers formuliert, der in diesem Fall wie folgt aussehen könnte: «Als Angreifer muss ich ein Passwort mit einer Länge von mindestens 12 Zeichen erraten, um mir Zugriff auf die Anwendung zu verschaffen.»
C1 sieht für die Umsetzung von Sicherheitsanforderungen vier Schritte vor: Zunächst müssen die notwendigen Anforderungen ermittelt und ausgewählt werden. Ein Entwickler bedient sich zu diesem Zweck am besten an einer Standardquelle – beispielsweise dem oben vorgestellten ASVS – und entscheidet, welche Anforderungen in seiner Anwendung oder in einer bestimmten Version davon enthalten sein sollen. Dabei ist es wichtig, anfangs eine überschaubare und verwaltbare Zahl an Anforderungen für eine Version oder einen Sprint auszuwählen, und diesen Schritt dann für jede Version bzw. jeden Sprint zu wiederholen, sodass die Anwendung nach und nach über mehr Sicherheitsfunktionalität verfügt. Auf diesen Schritt folgt die Untersuchung und Dokumentation, bei der ein Entwickler die vorhandene Anwendung mit den ausgewählten Sicherheitsanforderungen abgleicht, um festzustellen, ob die Anforderungen bereits erfüllt werden, oder ob eine weitere Entwicklung erforderlich ist. Zum Abschluss dieser Phase werden die Ergebnisse dieses Abgleichs dokumentiert. Muss die Anwendung angepasst werden, nimmt der Entwickler entsprechende Änderungen am Code vor, sodass die gewünschte neue Funktionalität aufgenommen wird oder unsichere Optionen entfernt werden. Dieser Schritt umfasst somit die Implementierung. Abschließend sollte anhand von Testszenarien überprüft werden, ob neue Funktionalitäten oder zuvor unsichere Optionen ordnungsgemäß hinzugefügt bzw. entfernt wurden.
Die gesamte Sicherheitsfunktionalität einer Applikation hängt von solchen Sicherheitsanforderungen ab. Je mehr Aufmerksamkeit dem Thema Sicherheit schon am Anfang der Entwicklung geschenkt wird, desto mehr Schwachstellen können präventiv verhindert werden. Neben Sicherheitslücken können dadurch auch unnötige Kosten vermieden werden, denn je später ein Fehler in der Entwicklung oder sogar erst in der Produktion entdeckt und behoben wird, desto höher der Aufwand für dessen Behebung. Laut der sogenannten «Rule of Ten», oder auch Zehnerregel, verzehnfacht sich sowohl der zeitliche als auch der finanzielle Aufwand mit jeder weiteren Phase in der Entstehung einer Anwendung. [3]
C2: Nutzung von Sicherheitsframeworks und Bibliotheken
C2 (Leverage Security Frameworks and Libraries) legt den Einsatz vorhandener Code-Bibliotheken und Sicherheitsframeworks nahe, da sich damit sicherheitsbezogene Design- und Implementierungsfehler vermeiden lassen. Oftmals sind nicht ausreichend Wissen, Zeit oder Budget vorhanden, um Sicherheitsfunktionen von Grund auf zu entwickeln und fehlerfrei zu implementieren. Deswegen sollten sich Entwickler bereits existierender und in der Praxis erprobter Sicherheitsframeworks und Bibliotheken bedienen; diese bieten eine gute Ausgangslage, um die in Bezug auf Anwendungssicherheit gesteckten Ziele zu erreichen.
Bei der Integration solcher Drittanbieter-Frameworks oder -Bibliotheken ist jedoch unbedingt darauf zu achten, dass nur Frameworks und Bibliotheken von vertrauenswürdigen Quellen eingesetzt werden, die zum einen aktiv gewartet und zum anderen von vielen Anwendungen genutzt werden. Des Weiteren sollte eine Bestandsliste mit allen Bibliotheken erstellt und regelmäßig aktualisiert werden. Nicht nur die Bestandsliste, sondern auch sämtliche darin enthaltenen Bibliotheken und zugehörigen Komponenten sind stets auf dem aktuellen Stand zu halten. Zum Identifizieren von Abhängigkeiten kann auf Tools wie OWASP Dependency Check [4] oder RetireJS [5] zurückgegriffen werden. Darüber hinaus sollten sich Entwickler stets informieren, ob Sicherheitslücken im Code von Drittanbietern bekannt sind. Zu guter Letzt empfiehlt es sich gemäß Good Practices aus dieser Proactive Control, die Angriffsfläche der Anwendung zu reduzieren, indem nur der Teil einer Bibliothek verwendet wird, der auch wirklich erforderlich ist.
Sichere Frameworks und Bibliotheken können zum Vermeiden einer Vielzahl von Schwachstellen in Webanwendungen beitragen. Wesentlich ist dabei, den Überblick über sämtliche eingesetzte Bibliotheken und Frameworks zu behalten und diese jederzeit auf dem aktuellen Stand zu halten. Anderenfalls haben sie möglicherweise einen gegenteiligen Effekt und erhöhen nicht wie gewünscht die Sicherheit einer Anwendung, sondern dienen als Einfallstor für potenzielle Angreifer. [6]
C3: Sicherer Zugriff auf Datenbanken
C3 (Secure Database Access) beschäftigt sich mit dem sicheren Zugriff auf sämtliche Datenspeicher, einschließlich relationaler Datenbanken und NoSQL-Datenbanken. Die dabei im Einzelnen zu berücksichtigenden Prozesse umfassen unter anderem sichere Abfragen, Konfiguration, Authentifizierung und Kommunikation.
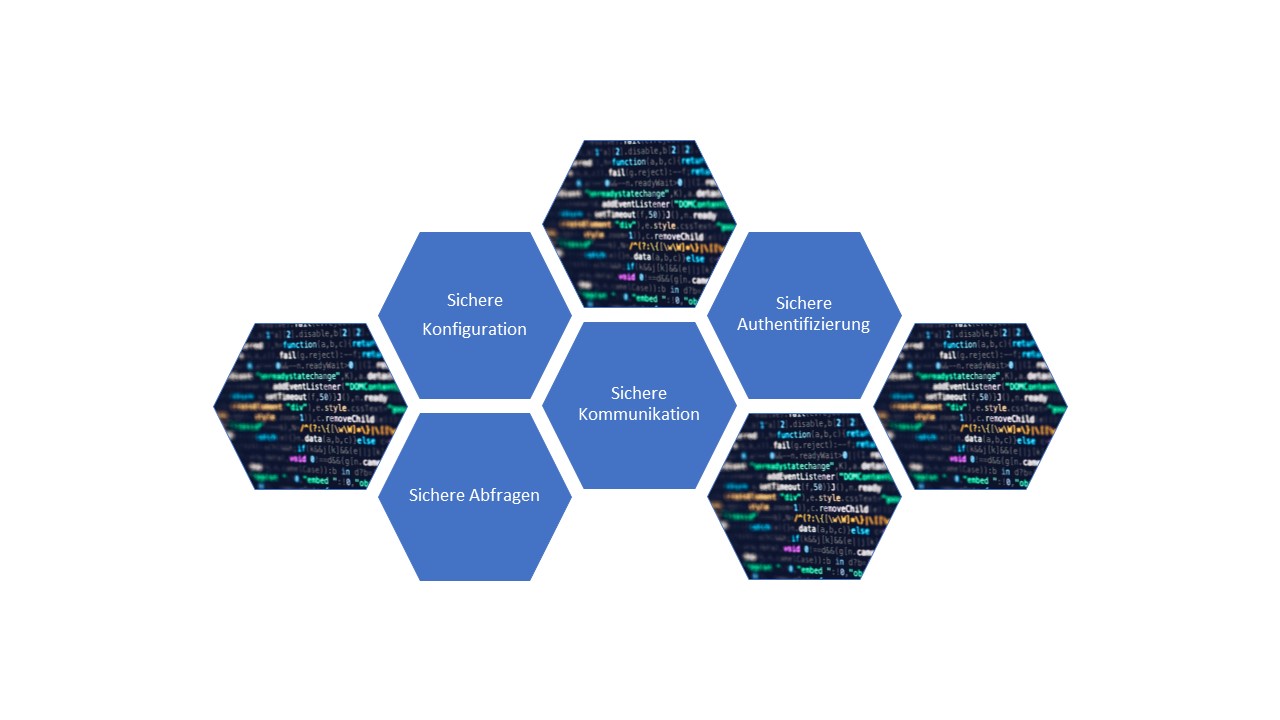
Sichere Abfragen haben einen besonders hohen Stellenwert, da sie dem Risiko von Injections ausgesetzt sind. Injection-Schwachstellen wie SQL Injections sind der Spitzenreiter der OWASP Top Ten für Webanwendungen und stellen mit die gefährlichste Schwachstellenart für solche Applikationen dar. Diese Art von Schwachstelle ist verhältnismäßig einfach auszunutzen und kann weitreichende Folgen haben: Daten – oder sogar gesamte Datenbanken – können gestohlen, gelöscht oder manipuliert werden. Zu SQL Injection kann es kommen, wenn nicht vertrauenswürde Benutzereingaben dynamisch zu einer SQL-Abfrage hinzugefügt werden, oftmals durch die einfache Aneinanderreihung von Zeichenketten. Folglich sollten Benutzereingaben niemals als Teil von SQL-Befehlen interpretiert werden. Stattdessen sollten sogenannte «Prepared Statements» mit parametrisierten Abfragen verwendet werden, wodurch ein Benutzer in einer Abfrage lediglich die Parameter eingeben muss. [7]
Neben sicheren Abfragen ist auch eine sichere Konfiguration wesentlich. Datenbankmanagementsysteme (DBMS) verfügen nicht immer standardmäßig über eine sichere Konfiguration. Es muss daher darauf geachtet werden, dass die Sicherheitskontrollen des DBMS und der Host-Plattform aktiviert und ordnungsgemäß entsprechend der geltenden Good Practices gehärtet sind. Für die meisten gängigen DBMS sind hierzu Standards, Leitfäden und Richtwerte verfügbar.
Zudem muss gewährleistet werden, dass ein sicheres Authentifizierungsverfahren für den Zugriff auf die Datenbank implementiert ist. Sämtlicher Zugriff auf die Datenbank muss zuverlässig authentifiziert werden und die Authentifizierung muss über einen sicheren Kanal erfolgen.
Abschließend ist für eine sichere Kommunikation zu sorgen. Die meisten DBMS unterstützen unterschiedlichste Kommunikationswege, beispielsweise Dienste, APIs etc., die in der Praxis sowohl sicher (mit zwingender Authentisierung und Verschlüsselung) als auch unsicher (ohne Authentisierung und Verschlüsselung) konfiguriert werden. Bei der Auswahl der Kommunikationsmethode sollten bestenfalls nur die unter «C8: Durchgängiger Schutz von Daten» im zweiten Teil des Artikels erläuterten Verfahren in Erwägung gezogen werden.
In Kombination tragen all diese Maßnahmen zur Verhinderung von Injection-Angriffen – und damit zur Verhinderung einer der laut OWASP kritischsten Kategorie von Schwachstellen – bei.
C4: Encodierung und Maskierung von Daten
C4 (Encode and Escape Data) bietet eine weitere Verteidigungsmaßnahme gegen Injection-Angriffe. Encodierung (Output Encoding) umfasst die Umwandlung von Sonderzeichen in eine andere, äquivalente Form, die im Ziel-Interpreter kein erhöhtes Risiko verursacht: zum Beispiel wird < im HTML-Kontext zu <. Bei der Maskierung von Daten (Escaping) wird vor einem Zeichen/einer Zeichenfolge ein Sonderzeichen hinzugefügt, um zu verhindern, dass das Zeichen/die Zeichenfolge falsch interpretiert wird; so wird beispielsweise vor « (doppelte Anführungszeichen) ein \ gesetzt, damit die Zeichenfolge als Text und nicht als Schlusszeichen eines Strings interpretiert wird.
Die Encodierung von Output sollte erst unmittelbar vor der Übertragung des Inhalts an den Ziel-Interpreter erfolgen, denn wird diese Maßnahme zu früh beim Verarbeiten einer Anfrage umgesetzt, kann dies beim Verwenden des Inhalts in anderen Komponenten des Programms zu Problemen führen. Es kann zur doppelten Maskierung von Daten kommen, sodass es sein kann, dass Inhalte zum Beispiel im Kontext einer Benutzeroberfläche nicht mehr richtig dargestellt werden können.
«Contextual Output Encoding», d. h. das kontextuelle Encodieren von Output, ist eine Programmiertechnik, die für das Verhindern von Cross-Site-Scripting-Angriffen (XSS) wichtig ist. Diese Methode wird bei der Entwicklung einer Benutzerschnittstelle auf Output angewendet, unmittelbar bevor nicht vertrauenswürdige Daten dynamisch in der Ausgabe hinzugefügt werden. Die Art der Encodierung hängt dabei von der Stelle bzw. dem Kontext im Dokument ab, an der oder in dem Daten angezeigt oder gespeichert werden. Zu den Encodierungsverfahren, die idealerweise zur Entwicklung einer sicheren Benutzerschnittstelle eingesetzt werden, zählen unter anderem HTML Entity Encoding, HTML Attribute Encoding und JavaScript Encoding.
Darüber hinaus gibt es weitere Arten von Encoding/Escaping, um eine Anwendung gegen andersartige Injection-Angriffe zu schützen; dazu zählen unter anderem OS Command Escaping (Maskierung von Betriebssystem-Befehlen) als Maßnahme gegen Command Injection-Schwachstellen oder die Maskierung von XML-Attributen zur Vorbeugung von XML Path Injection.
Zusammenfassend können Anwendungen mithilfe von Encoding und Escaping vor allen Dingen gegen Injection- und Cross-Site-Scripting-Schwachstellen geschützt werden.
C5: Validierung aller Eingaben
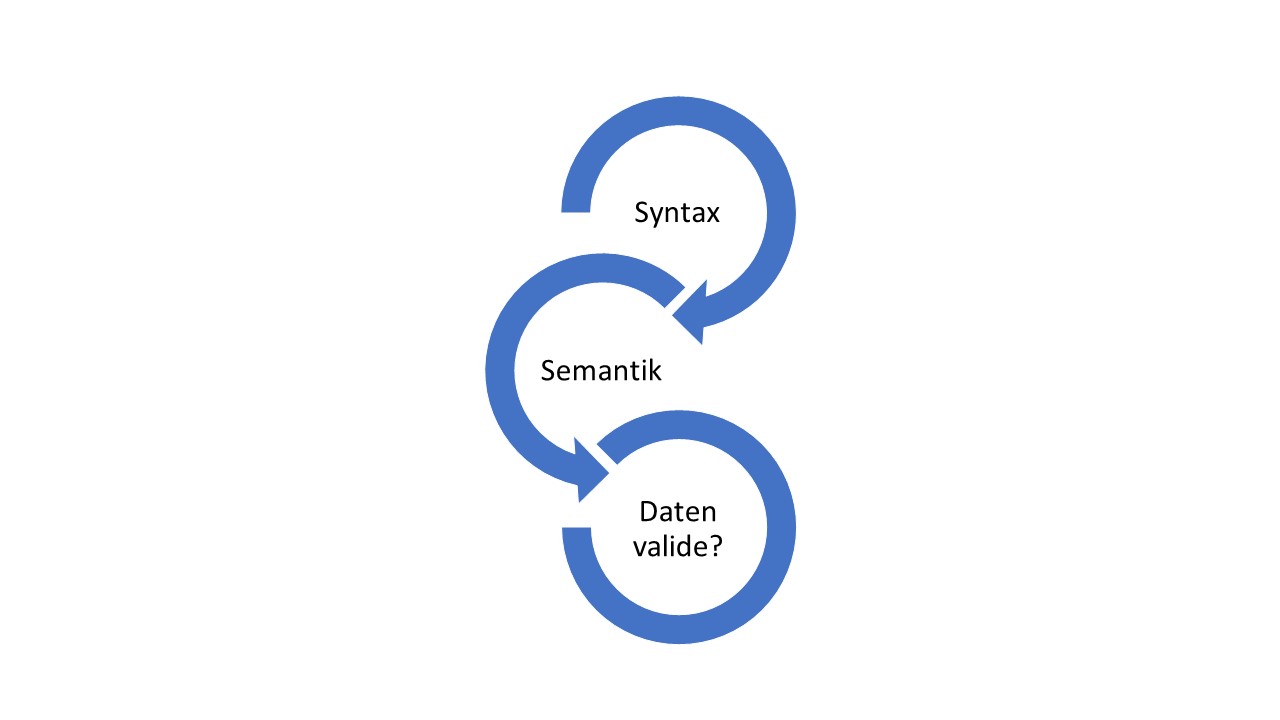
C5 (Validate All Inputs), Input-Validierung, empfiehlt, dass nur Daten, die ein vorgesehenes Format aufweisen, in eine Komponente eines Softwaresystems gelangen sollten. Um dies durchzusetzen, muss eine Anwendung zunächst prüfen, ob alle Daten sowohl syntaktisch als auch semantisch – in genau dieser Reihenfolge – «valide» sind, bevor sie weiterverarbeitet werden. Konkret bedeutet dies in Bezug auf die Syntax, dass die Daten die erwartete äußerliche Form haben. Das folgende Beispiel verdeutlicht dieses Prinzip: Ein Benutzer wird in einer Anwendung aufgefordert, ein Datum einzugeben, um einen bestimmten Vorgang durchzuführen. Die Anwendung sollte vom «Worst Case» ausgehen; das bedeutet, dass der Benutzer SQL-Injection-Nutzdaten eingibt. Somit muss sie sicherstellen, dass die Benutzereingabe genau dem erwarteten Format eines Datums entspricht, z. B. DD.MM.YYYY (syntaktische Prüfung). Semantisch sind Daten nur dann gültig, wenn sie sich im jeweiligen Kontext in einem zulässigen Bereich bewegen. Beispielsweise darf bei der Auswahl eines Liefertermins das Datum nicht in der Vergangenheit liegen.
Zur Validierung der Eingabe-Syntax gibt es zwei sehr bekannte Methoden: Blacklisting und Whitelisting. Beim Blacklisting wird überprüft, ob Daten bekannte bösartige Inhalte umfassen, wohingegen beim Whitelisting geprüft wird, ob die Daten festgelegten Positivregeln entsprechen. Für die sichere Softwareentwicklung ist Whitelisting dem Blacklisting vorzuziehen, da es weniger fehleranfällig ist und dazu beiträgt, die Angriffsfläche einer Anwendung zu reduzieren; Blacklisting hingegen ist fehleranfälliger und kann auf verschiedenen Wegen umgangen werden. Es eignet sich jedoch gut dafür, offensichtliche Angriffe zu erkennen und gegebenenfalls zu unterbinden.
Im Allgemeinen sollte die Eingabevalidierung wie sämtliche sicherheitsrelevante Prüfungen wenn immer möglich auf dem Server erfolgen. Eine clientseitige Validierung kann zwar für einige Funktionen und Sicherheitsaspekte nützlich sein und die Benutzerfreundlichkeit erhöhen, kann jedoch zu leicht umgangen werden, wodurch eine solide serverseitige Validierung umso wichtiger ist.
Ein weiteres Verfahren zur Validierung von Eingaben sind reguläre Ausdrücke (Regular Expressions), anhand deren geprüft wird, ob Daten einem bestimmten Muster entsprechen. Solche regulären Ausdrücke sind allerdings komplex in der Erstellung und dabei implementierte Fehler können wiederum weitere Schwachstellen verursachen. Somit sollte diese Maßnahme mit Bedacht und nur bei ausreichend vorhandener Erfahrung und Kenntnis eingesetzt werden.
Generell ist zu berücksichtigen, dass die Input-Validierung alleine Daten nicht automatisch sicher macht, da bestimmte Eingaben zwar laut Validierung zulässig, aber dennoch gefährlich sein können. So kann eine gültige E-Mail-Adresse etwa eine SQL-Injection enthalten. Daher sollten neben der Validierung von Eingaben immer zusätzliche Verteidigungsmaßnahmen herangezogen werden, zum Beispiel die Parametrisierung von Abfragen (siehe C3) oder Escaping (siehe C4).
Auch bei der Validierung von serialisierten Daten ist Vorsicht geboten: Ein System wird einem Risiko ausgesetzt, wenn Daten, die nicht vertrauenswürdig sind oder die von einem Angreifer manipuliert werden können, deserialisiert werden. Im besten Fall sollte eine Anwendung so gestaltet werden, dass serialisierte Objekte aus nicht vertrauenswürdigen Quellen abgelehnt werden oder die Deserialisierung nur in begrenztem Umfang und ausschließlich für einfache Daten erfolgt.
Eine weitere Herausforderung für die Validierung von Eingaben sind unerwartete Benutzereingaben, die auch unter dem Begriff «Massenzuweisung» bekannt sind. Bei manchen Frameworks werden Parameter aus HTTP-Anfragen automatisch an serverseitige Objekte gebunden. Dadurch kann ein Angreifer möglicherweise auch serverseitige Objekte aktualisieren, die eigentlich nicht verändert werden sollen. Dies könnte der Angreifer zum Erweitern seiner Rechte ausnutzen. Um das Risiko der Massenzuweisung zu verhindern, sollten Datentransferobjekte (DTOs) eingesetzt werden, damit Eingaben nicht automatisch an Objekte gebunden werden. Eine weitere Möglichkeit besteht darin, die automatische Bindung von Eingaben an Objekte zu deaktivieren und für jede Seite oder Funktion Whitelisting-Regeln einzurichten, die festlegen, bei welchen Feldern das automatische Binding zulässig ist.
Alle modernen Programmiersprachen und die meisten Frameworks verfügen über Bibliotheken oder Funktionen, die zur Validierung von Daten eingesetzt werden sollten. Wie bereits in C2 erläutert, sollte anstatt eigenständiger Entwicklungen auf vorhandene und bewährte Frameworks und Bibliotheken zurückgegriffen werden. Sie decken die gängigen Datentypen und Anforderungen ab und können nach Bedarf durch eigene Logik ergänzt werden.
Insgesamt kann die Validierung von Eingaben dazu beitragen, die Angriffsfläche von Anwendungen zu verringern und mögliche Angriffe zu erschweren. Nichtsdestotrotz darf sie nicht als allgemeingültige zuverlässige Sicherheitsmaßnahme betrachtet werden, da sie auf bestimmte Datenformen und Angriffe abzielt. Input-Validierung sollte nicht als primäre Verteidigungsmaßnahme gegen Cross-Site Scripting, SQL Injection oder weitere Angriffe eingesetzt werden.
Ausblick
Mit C5 schließt dieser erste Teil des Artikels ab, in dem Sie sich einen Überblick über die ersten fünf präventiven Sicherheitsmaßnahmen der OWASP Top 10 Proactive Controls verschaffen konnten. Der folgende zweite Teil wird näher auf die Proactive Controls C6 bis C10 eingehen sowie ein übergreifendes Fazit ziehen.
Über Oneconsult
Die Oneconsult-Unternehmensgruppe ist seit 2003 Ihr renommierter Schweizer Cybersecurity Services Partner mit Büros in der Schweiz und Deutschland und 2000+ weltweit durchgeführten Security-Projekten.
Erhalten Sie kompetente Beratung vom inhabergeführten und herstellerunabhängigen Cybersecurity-Spezialisten mit 40+ hochqualifizierten Cybersecurity Experten, darunter zertifizierte Ethical Hacker / Penetration Tester (OPST, OPSA, OSCP, OSCE, GXPN), IT-Forensiker (GCFA, GCFE, GREM, GNFA), ISO Security Auditoren (ISO 27001 Lead Auditor, ISO 27005 Risk Manager, ISO 27035 Incident Manager) und dedizierte IT Security Researcher, um auch Ihre anspruchsvollsten Herausforderungen im Informationssicherheitsbereich zu bewältigen. Gemeinsam gehen wir Ihre externen und internen Bedrohungen wie Malware-Infektionen, Hacker-Attacken und APT sowie digitalen Betrug und Datenverlust mit Kerndienstleistungen wie Penetration Tests / Ethical Hacking, APT Tests unter Realbedingungen und ISO 27001 Security Audits an. Bei Notfällen können Sie rund um die Uhr (24 h x 365 Tage) auf die Unterstützung des Digital Forensics & Incident Response (DFIR) Expertenteams von Oneconsult zählen.
[1]: https://owasp.org/www-project-proactive-controls/
[2]: https://github.com/OWASP/ASVS
[3]: https://www.researchgate.net/publication/337343379_Rule_of_Ten
[4]: https://jeremylong.github.io/DependencyCheck/
[5]: https://github.com/retirejs/retire.js/
[6]: https://owasp.org/www-project-top-ten/
[7]: https://cheatsheetseries.owasp.org/cheatsheets/SQL_Injection_Prevention_Cheat_Sheet.html



